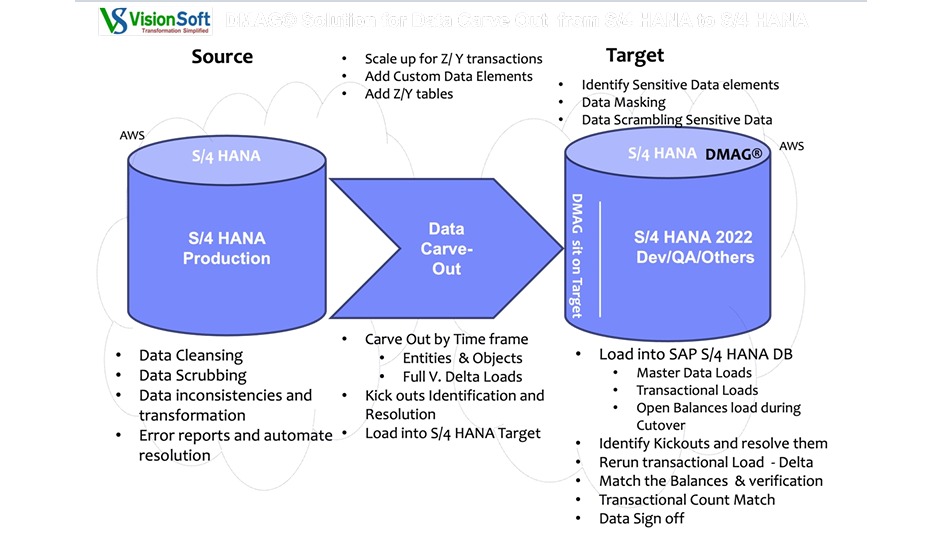
Organizations often require development, testing, training, and quality assurance environments that behave like real production systems. However, copying the entire production database into non-production environments can be expensive, time-consuming, and risky from a data privacy perspective. Data Carveout provides a smarter and more efficient approach by extracting only the relevant subset of data required for specific scenarios.
A data carveout is the selective extraction of master data, transactional data, and configuration data from a production system into development or testing environments. Instead of cloning the full system, carveouts focus on meaningful datasets such as a specific business process, region, product line, or time period. This allows teams to work with realistic data while significantly reducing system size, refresh time, and infrastructure costs.
Our DMAG®-powered Data Carveout framework enables organizations to create targeted datasets that support development, testing, analytics, and training activities. By applying governed selection rules and automated extraction techniques, the framework ensures that only relevant data is transferred into non-production environments. This targeted approach allows project teams to test real business scenarios without the overhead of maintaining full database copies.
Data carveouts can be designed based on multiple criteria depending on business needs. For example, organizations may carve data by business process such as Order-to-Cash or Procure-to-Pay, by time frame such as the last six or twelve months of transactions, or by geography, plant, or business unit. This flexibility enables organizations to focus on the exact data required for a specific project, rollout, or training program.
A key component of the data carveout process is data privacy and security. Production systems often contain sensitive information such as personally identifiable information (PII), financial data, and confidential customer details. The carveout framework identifies these sensitive fields and applies masking or scrambling techniques to protect them before loading the dataset into non-production environments. This ensures compliance with data protection regulations and internal security policies.
Data carveouts are widely used in several enterprise scenarios. Development and QA teams benefit from faster environment refresh cycles with smaller datasets. Training environments can simulate real production behavior while protecting sensitive information. During system upgrades, migrations, or regional rollouts, carveouts allow organizations to focus on a limited dataset for pilot testing before scaling across the enterprise.
By implementing a structured data carveout strategy, organizations gain faster development cycles, improved testing accuracy, lower infrastructure costs, and stronger data privacy protection. The DMAG Data Carveout approach provides a repeatable and governed process that helps organizations maintain efficient, secure, and scenario-ready non-production environments.
Data Carveout Demo